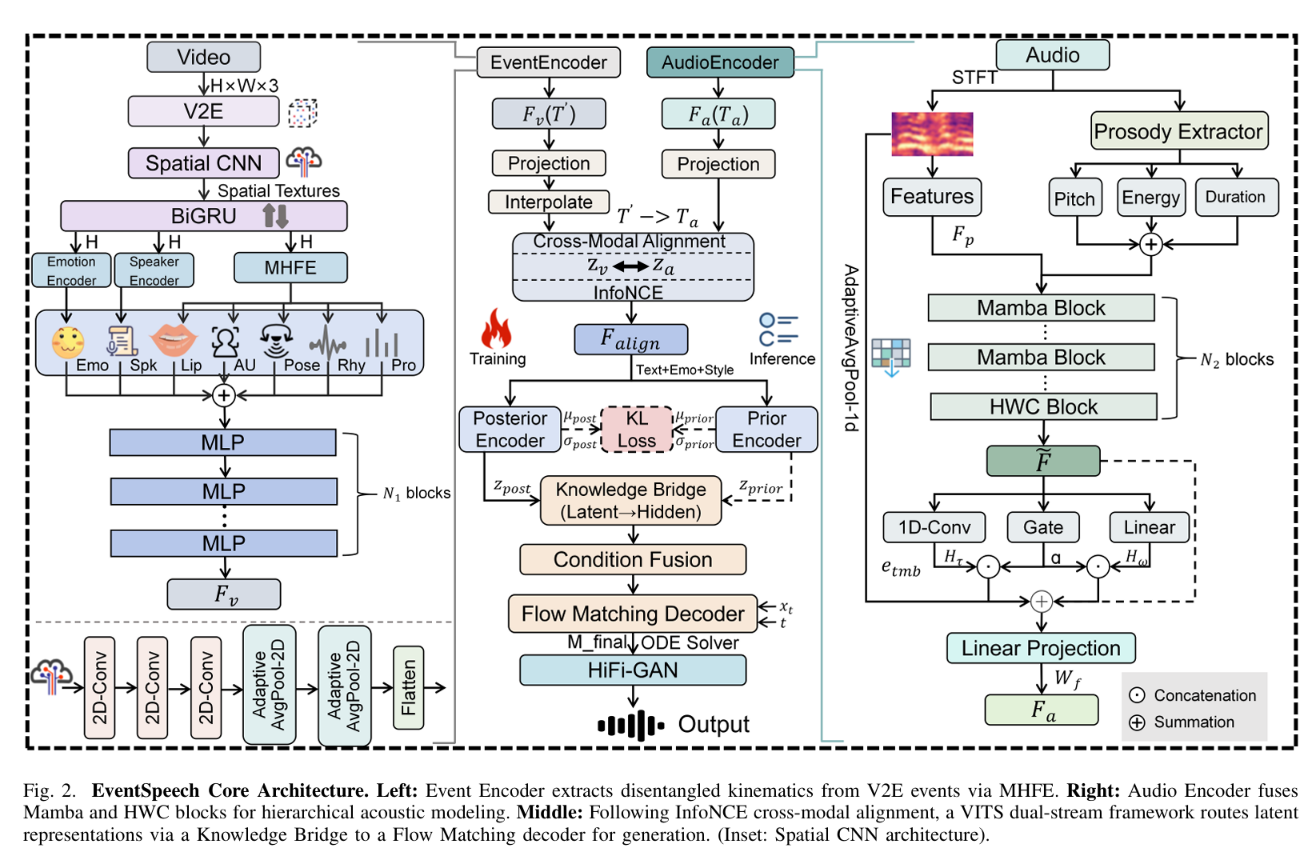
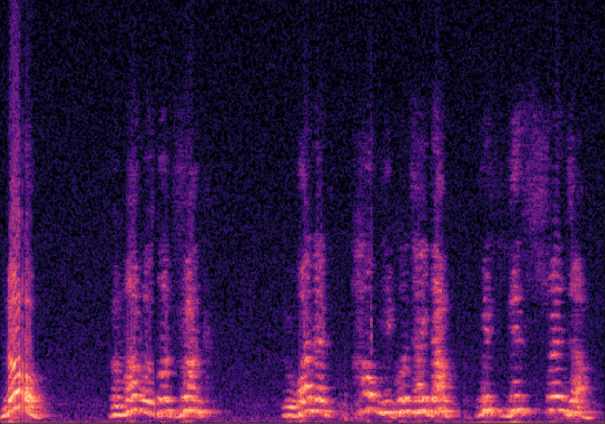
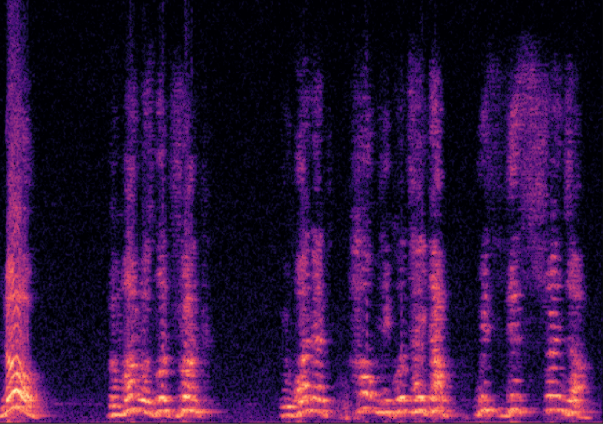
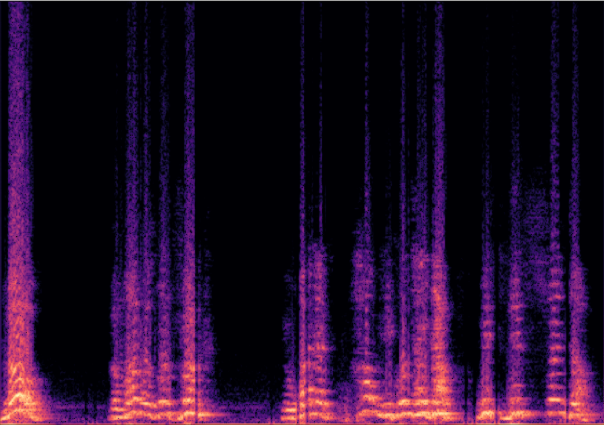
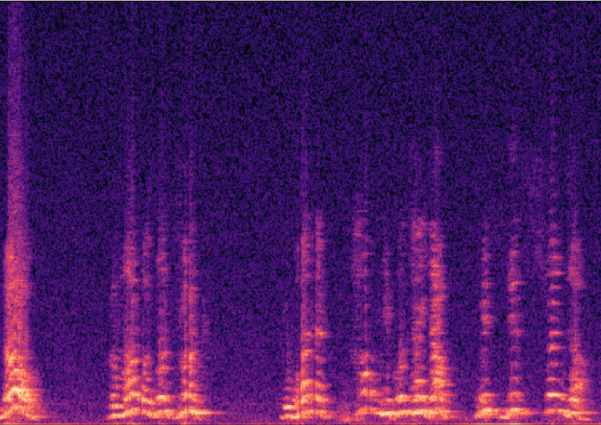
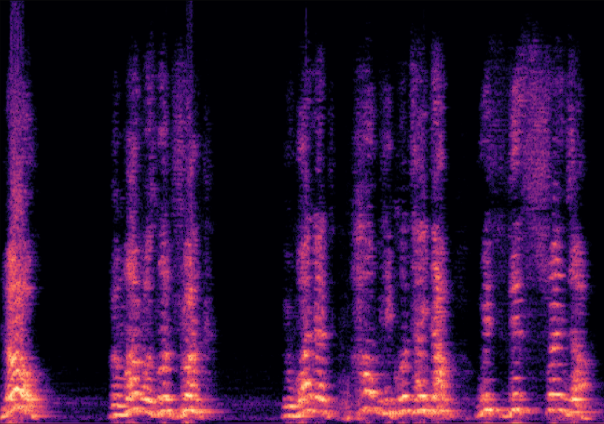
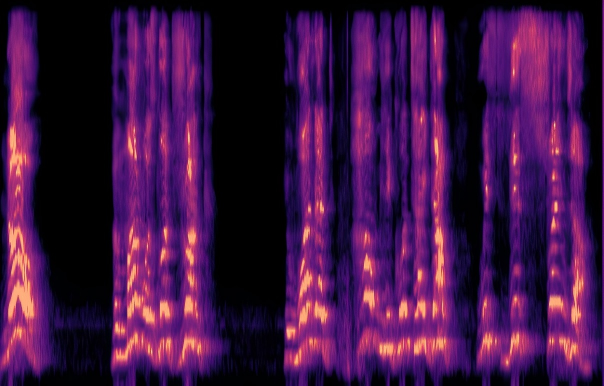
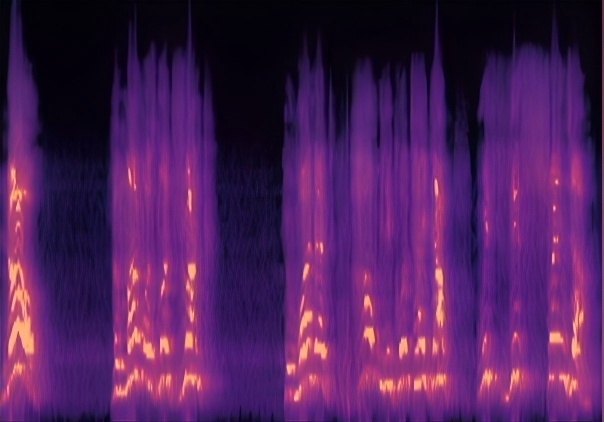
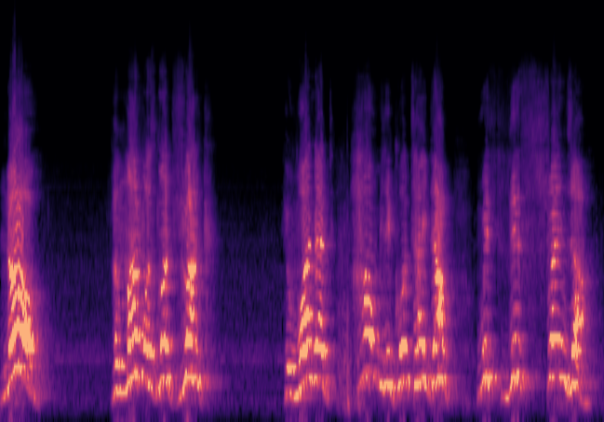
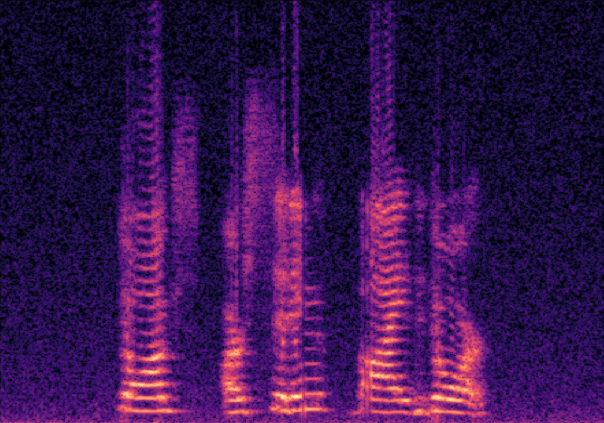
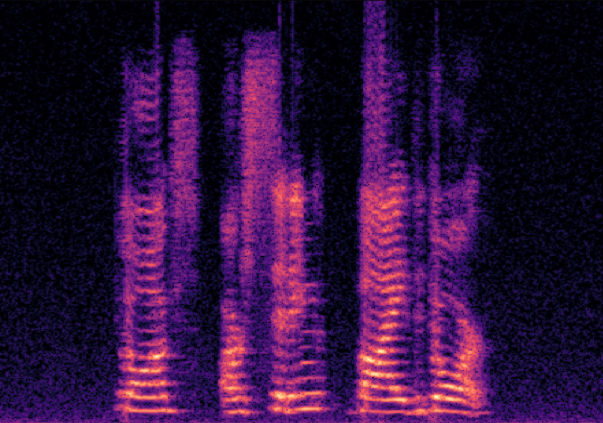
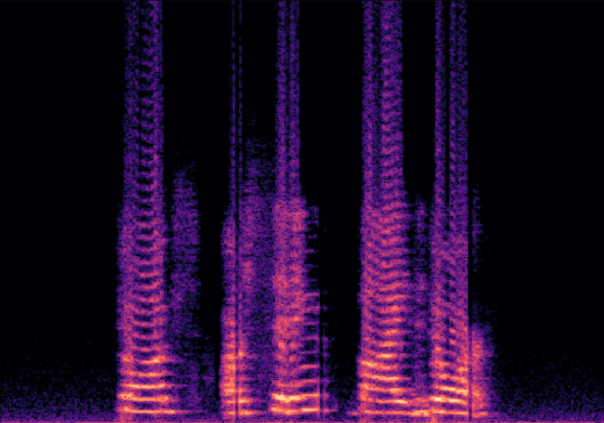
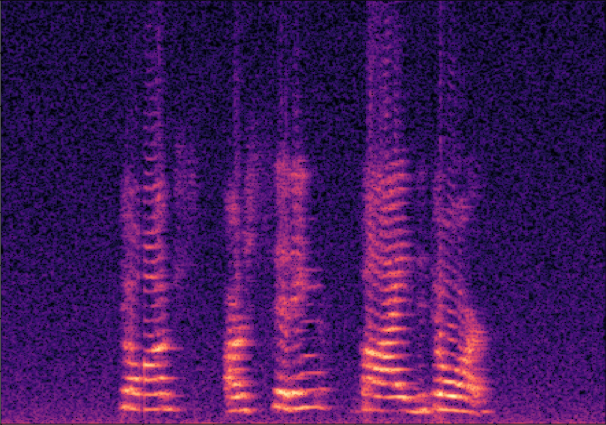
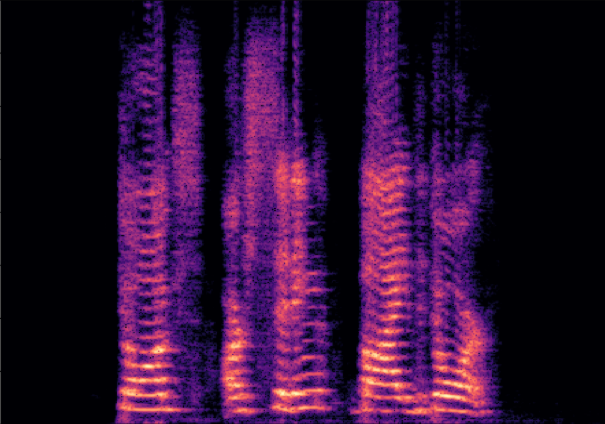
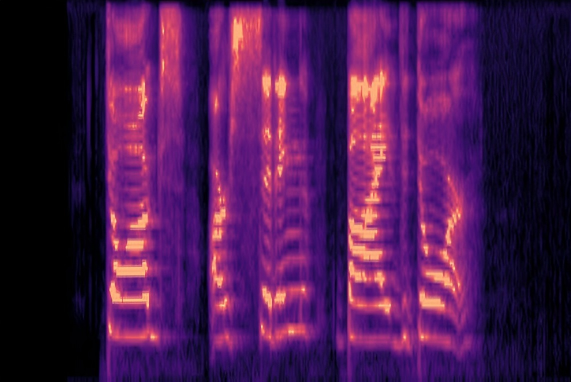
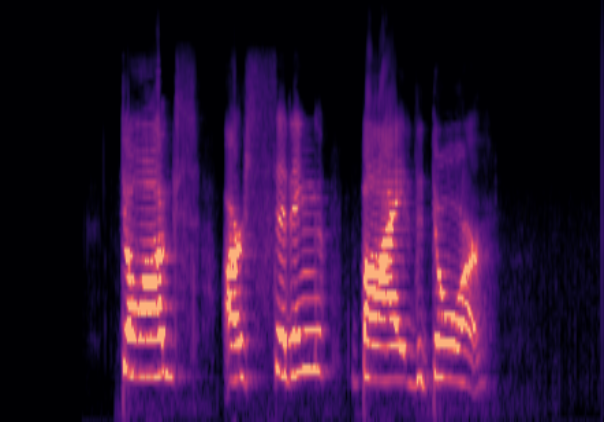
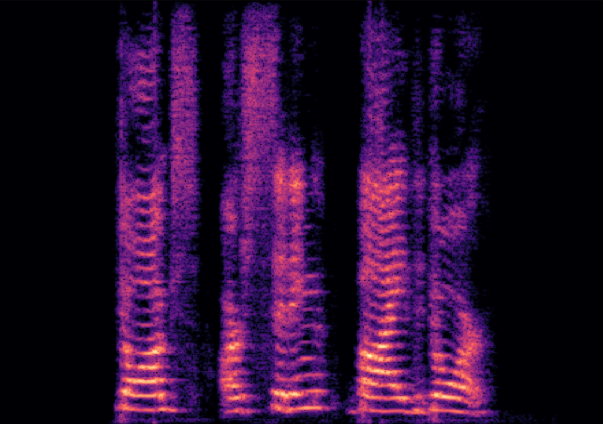
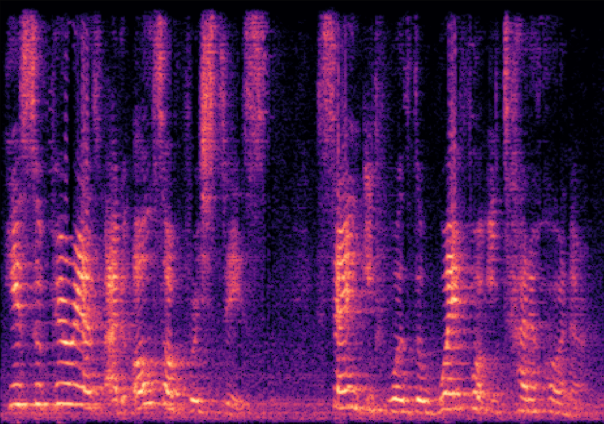
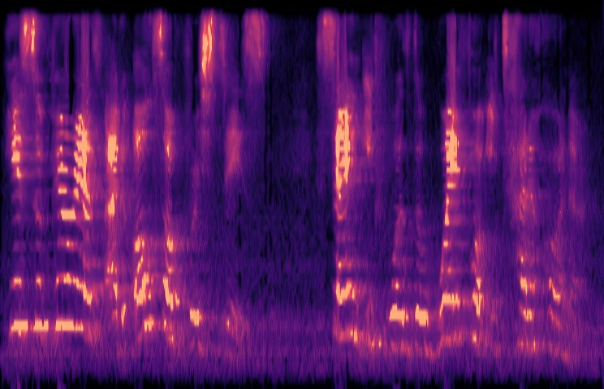
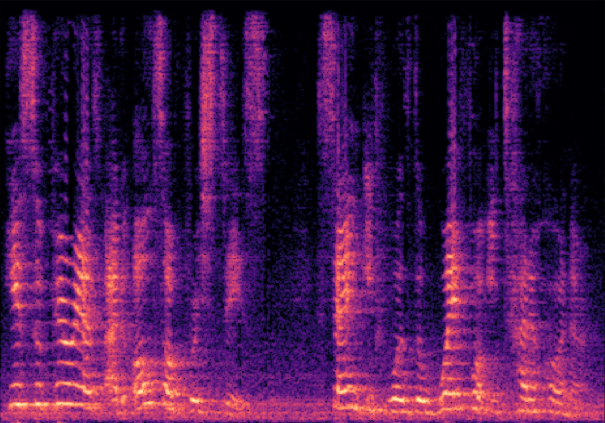
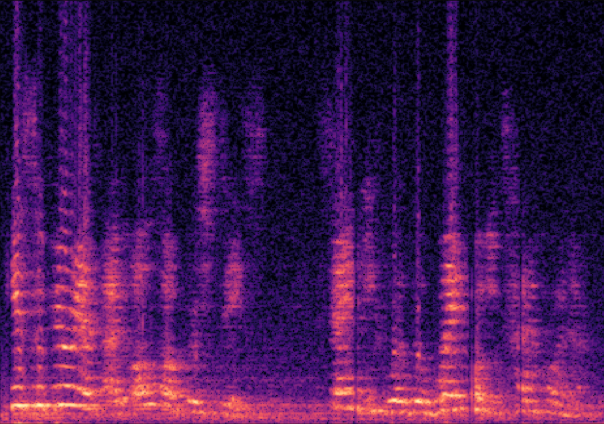
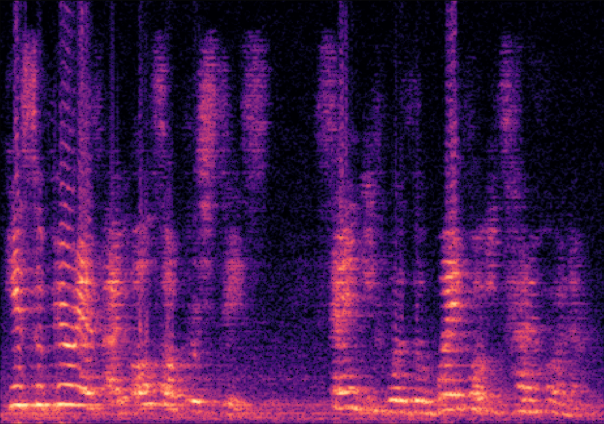
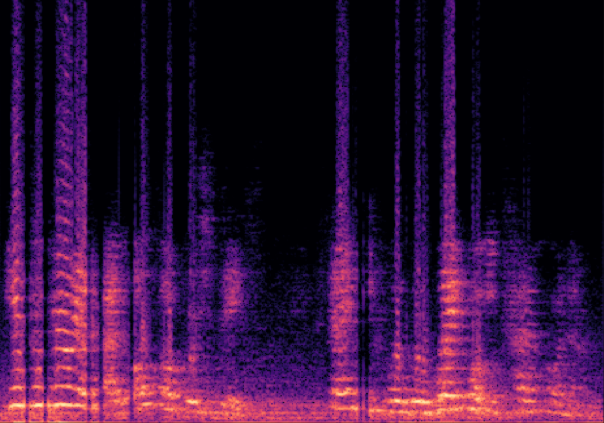
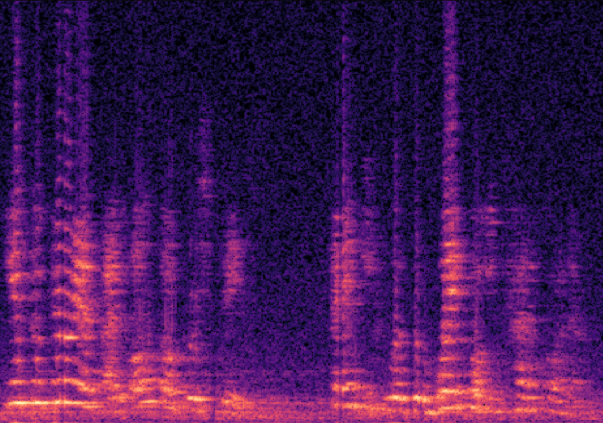
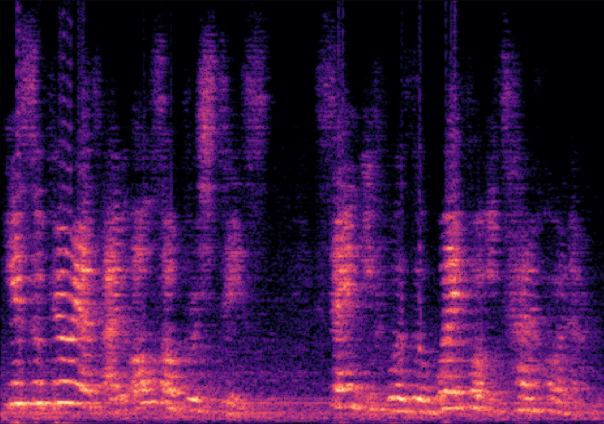
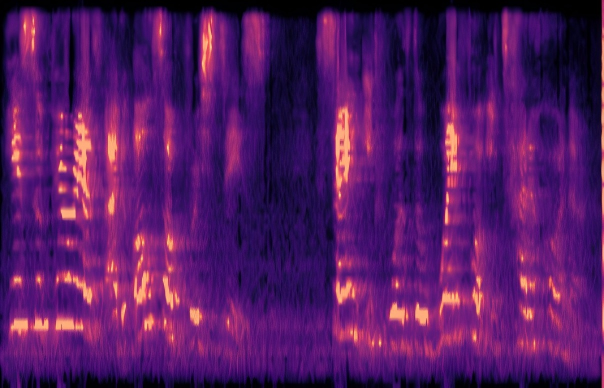
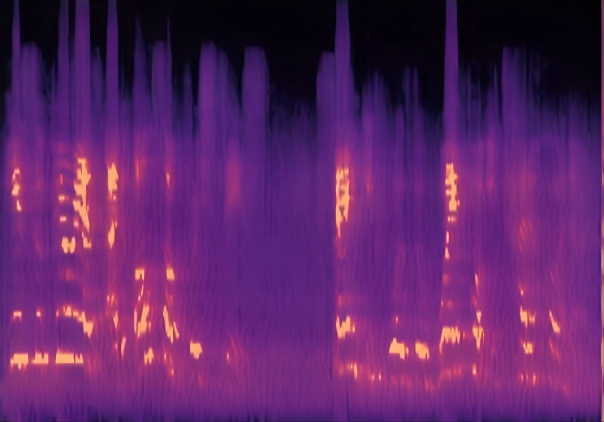
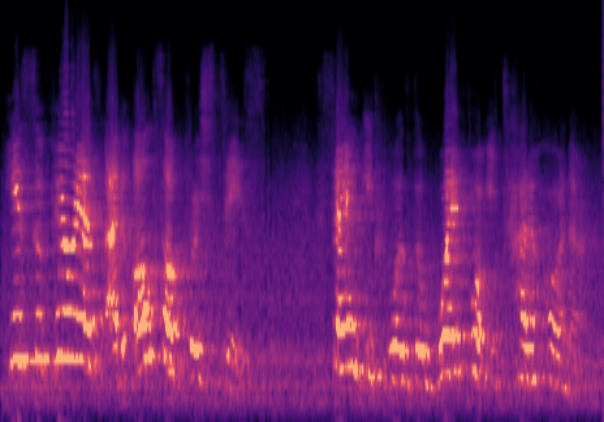
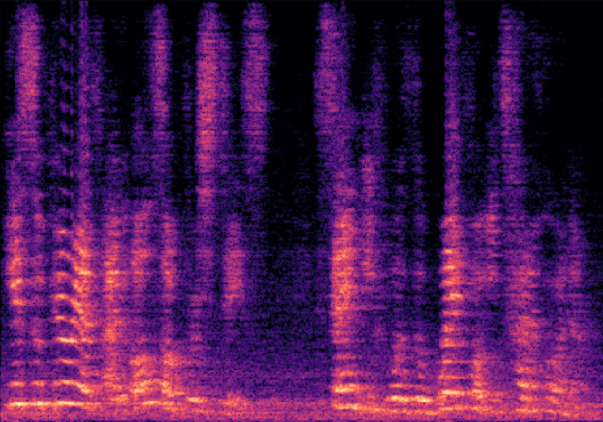
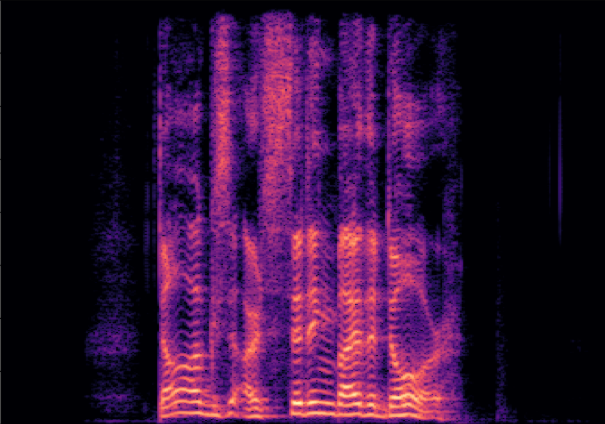
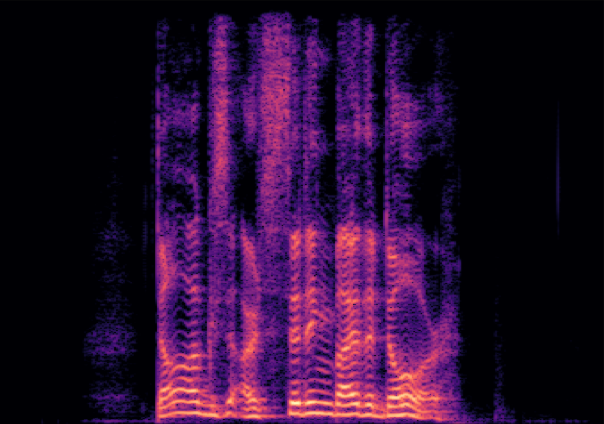
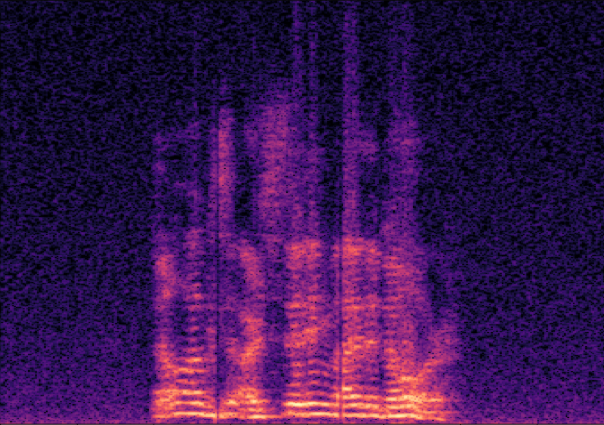
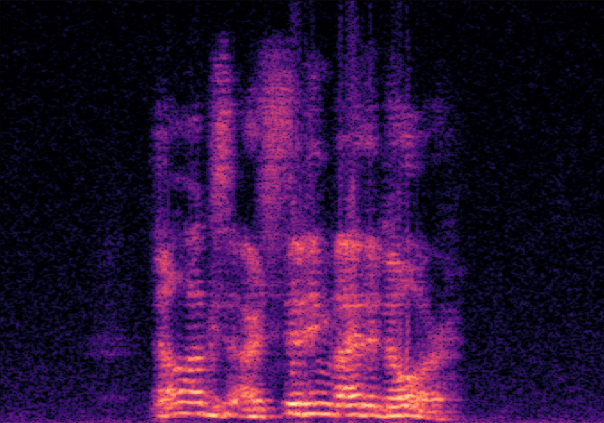
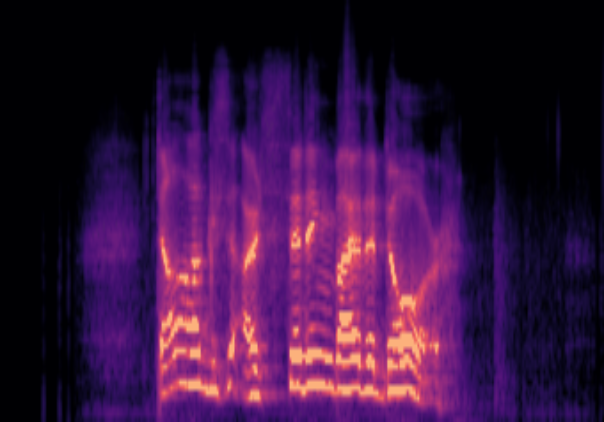
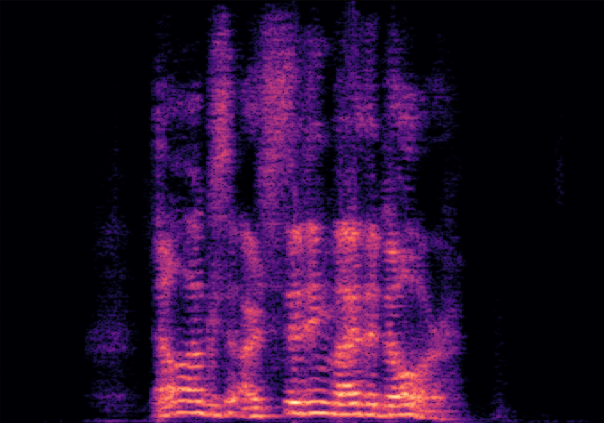
Traditional RGB-based speech generation faces Temporal Granularity Mismatch since fixed camera exposure times inevitably blur the high-frequency articulatory transients essential for rendering emotional speech. To break this ceiling, we propose EventSpeech as a novel text-conditioned framework pioneering the use of neuromorphic events for expressive speech generation, since these microsecond-precise events naturally align with acoustic waveform dynamics. Our architecture integrates a dedicated Event Encoder to model sparse neuromorphic events alongside a multi-scale Audio Encoder featuring a Hierarchical Wavelet Contextualizer (HWC). A bidirectional alignment mechanism seamlessly synchronizes linguistic content and visual dynamics with dense acoustic features. Furthermore, we construct EVT-SPK as the first benchmark comprising large-scale synthetic data and real-world recordings from specialized neuromorphic hardware. Extensive evaluations demonstrate that EventSpeech significantly outperforms current baselines by preserving fine-grained emotions and resisting motion blur to establish a new paradigm for multimodal speech generation.